To build and effectively operate extreme-scale high-performance computing (HPC) systems, the US Department of Energy cites several key challenges, including resilience, or efficient and correct operation despite the occurrence of faults or defects in system components that can cause errors. These innovative systems require equally innovative components designed to communicate and compute at unprecedented rates, scales, and levels of complexity, increasing the probability for hardware and software faults. This research project offers a structured hardware and software design approach for improving resilience in extreme-scale HPC systems so that scientific applications running on these systems generate accurate solutions in a timely and efficient manner.
Frequently used in computer engineering, design patterns identify problems and provide generalized solutions through reusable templates. Using a novel resilience design pattern concept, this project identifies and evaluates repeatedly occurring resilience problems and coordinates solutions throughout hardware and software components in HPC systems. This effort creates comprehensive methods and metrics by which system vendors and computing centers can establish mechanisms and interfaces to coordinate flexible fault management across hardware and software components and optimize the cost-benefit trade-offs among performance, resilience, and power consumption. Reusable templates of these patterns offer resilience portability across different HPC system architectures and permit design space exploration and adaptation to different design trade-offs. For more information, please visit ornlwiki.atlassian.net/wiki/display/RDP.
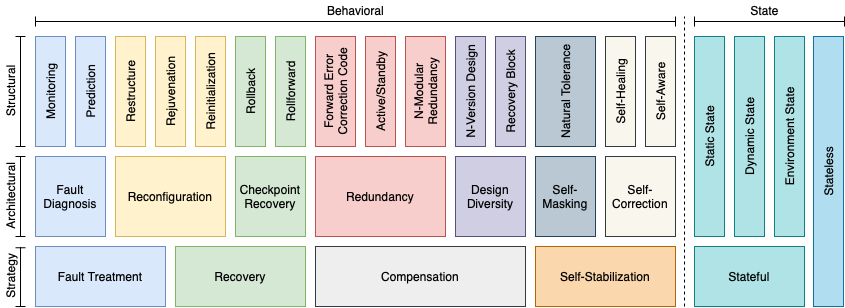
Figure: Classification of resilience design patterns
Latest Resilience Design Pattern specification:
- Christian Engelmann, Rizwan Ashraf, Saurabh Hukerikar, Mohit Kumar, and Piyush Sao. Resilience Design Patterns: A Structured Approach to Resilience at Extreme Scale (Version 2.0). Technical Report, ORNL/TM-2022/2809, Oak Ridge National Laboratory, Oak Ridge, TN, USA, August 1, 2022. DOI 10.2172/1922296.



Prominent Solutions
Funding Sources
- Early Career Research Program, Office of Advanced Scientific Computing Research, Office of Science, U.S. Department of Energy
Participating Institutions
In the News
2021-03-30: DOE Advanced Scientific Computing Research. New Approach to Fault Tolerance Means More Efficient High-Performance Computers.
2015-07-15: ASCR Discovery. Mounting a charge. Early-career awardees attack exascale computing on two fronts: Power and resilience.
2015-07-15: HPC Wire. Tackling Power and Resilience at Exascale.
Peer-reviewed Journal Publications
- Saurabh Hukerikar and Christian Engelmann. Resilience Design Patterns: A Structured Approach to Resilience at Extreme Scale. Journal of Supercomputing Frontiers and Innovations (JSFI), volume 4, number 3, pages 4-42, October 1, 2017. South Ural State University Chelyabinsk, Russia. ISSN 2409-6008. DOI 10.14529/jsfi170301.
Peer-reviewed Conference Publications
- Saurabh Hukerikar and Christian Engelmann. PLEXUS: A Pattern-Oriented Runtime System Architecture for Resilient Extreme-Scale High-Performance Computing Systems. In Proceedings of the 25th IEEE Pacific Rim International Symposium on Dependable Computing (PRDC) 2020, pages 31-39, Perth, Australia, December 1-4, 2020. IEEE Computer Society, Los Alamitos, CA, USA. ISBN 978-1-7281-8004-5. ISSN 1555-094X. DOI 10.1109/PRDC50213.2020.00014. Acceptance rate 40.9% (18/44).
- Haewon Jeong, Yaoqing Yang, Christian Engelmann, Vipul Gupta, Tze Meng Low, Pulkit Grover, Viveck Cadambe, and Kannan Ramchandran. 3D Coded SUMMA: Communication-Efficient and Robust Parallel Matrix Multiplication. In Lecture Notes in Computer Science: Proceedings of the 26th European Conference on Parallel and Distributed Computing (Euro-Par) 2020, pages 392-407, Warsaw, Poland, August 24-28, 2020. Springer Verlag, Berlin, Germany. ISBN 978-3-030-57674-5. DOI 10.1007/978-3-030-57675-2_25. Acceptance rate 24.5% (39/159).

- Rizwan Ashraf, Saurabh Hukerikar, and Christian Engelmann. Pattern-based Modeling of Multiresilience Solutions for High-Performance Computing. In Proceedings of the 9th ACM/SPEC International Conference on Performance Engineering (ICPE) 2018, pages 80-87, Berlin, Germany, April 9-13, 2018. ACM Press, New York, NY, USA. ISBN 978-1-4503-5095-2. DOI 10.1145/3184407.3184421. Acceptance rate 23.7% (14/59).
- Rizwan Ashraf, Saurabh Hukerikar, and Christian Engelmann. Shrink or Substitute: Handling Process Failures in HPC Systems using In-situ Recovery. In Proceedings of the 26th Euromicro International Conference on Parallel, Distributed, and network-based Processing (PDP) 2018, pages 178-185, Cambridge, UK, March 21-23, 2018. IEEE Computer Society, Los Alamitos, CA, USA. ISBN 978-1-5386-4975-6. ISSN 2377-5750. DOI 10.1109/PDP2018.2018.00032. Acceptance rate 29.3% (27/92).
- Saurabh Hukerikar and Christian Engelmann. A Pattern Language for High-Performance Computing Resilience. In Proceedings of the 22nd European Conference on Pattern Languages of Programs (EuroPLoP) 2017, pages 12:1-12:16, Kloster Irsee, Germany, July 12-16, 2017. ACM Press, New York, NY, USA. ISBN 978-1-4503-4848-5. DOI 10.1145/3147704.3147718.
- Saurabh Hukerikar and Christian Engelmann. Havens: Explicit Reliable Memory Regions for HPC Applications. In Proceedings of the 20th IEEE High Performance Extreme Computing Conference (HPEC) 2016, pages 1-6, Waltham, MA, USA, September 13-15, 2016. IEEE Computer Society, Los Alamitos, CA, USA. DOI 10.1109/HPEC.2016.7761593.
Peer-reviewed Workshop Publications
- Mohit Kumar and Christian Engelmann. RDPM: An Extensible Tool for Resilience Design Patterns Modeling. In Lecture Notes in Computer Science: Proceedings of the 27th European Conference on Parallel and Distributed Computing (Euro-Par) 2021 Workshops: 14th Workshop on Resiliency in High Performance Computing (Resilience) in Clusters, Clouds, and Grids, pages 283-297, Lisbon, Portugal, August 30, 2021. Springer Verlag, Berlin, Germany. ISBN 978-3-031-06155-4. DOI 10.1007/978-3-031-06156-1_23. Acceptance rate 66.7% (4/6).
- Mohit Kumar and Christian Engelmann. Models for Resilience Design Patterns. In Proceedings of the 33rd International Conference on High Performance Computing, Networking, Storage and Analysis (SC) Workshops 2020: 10th Workshop on Fault Tolerance for HPC at eXtreme Scale (FTXS) 2020, pages 21-30, Atlanta, GA, USA, November 11, 2020. IEEE Computer Society, Los Alamitos, CA, USA. ISBN 978-0-7381-1080-6. DOI 10.1109/FTXS51974.2020.00008. Acceptance rate 66.7% (6/9).
- Piyush Sao, Christian Engelmann, Srinivas Eswar, Oded Green, and Richard Vuduc. Self-stabilizing Connected Components. In Proceedings of the 32nd International Conference on High Performance Computing, Networking, Storage and Analysis (SC) Workshops 2019: 9th Workshop on Fault Tolerance for HPC at eXtreme Scale (FTXS) 2019, pages 50-59, Denver, CO, USA, November 22, 2019. IEEE Computer Society, Los Alamitos, CA, USA. ISBN 978-1-7281-6013-9. DOI 10.1109/FTXS49593.2019.00011. Acceptance rate 60.0% (6/10).
- Rizwan Ashraf and Christian Engelmann. Performance Efficient Multiresilience using Checkpoint Recovery in Iterative Algorithms. In Lecture Notes in Computer Science: Proceedings of the 24th European Conference on Parallel and Distributed Computing (Euro-Par) 2018 Workshops: 11th Workshop on Resiliency in High Performance Computing (Resilience) in Clusters, Clouds, and Grids, pages 813-825, Turin, Italy, August 28, 2018. Springer Verlag, Berlin, Germany. ISBN 978-3-030-10549-5. DOI 10.1007/978-3-030-10549-5_63. Acceptance rate 50.0% (4/8).
- Saurabh Hukerikar and Christian Engelmann. Pattern-based Modeling of High-Performance Computing Resilience. In Lecture Notes in Computer Science: Proceedings of the 23rd European Conference on Parallel and Distributed Computing (Euro-Par) 2017 Workshops: 10th Workshop on Resiliency in High Performance Computing (Resilience) in Clusters, Clouds, and Grids, pages 557-568, Santiago de Compostela, Spain, August 29, 2017. Springer Verlag, Berlin, Germany. ISBN 978-3-319-75177-1. DOI 10.1007/978-3-319-75178-8_45. Acceptance rate 66.7% (4/6).
- Saurabh Hukerikar, Rizwan Ashraf, and Christian Engelmann. Towards New Metrics for High-Performance Computing Resilience. In Proceedings of the 26th ACM International Symposium on High-Performance Parallel and Distributed Computing (HPDC) 2017: 7th Workshop on Fault Tolerance for HPC at eXtreme Scale (FTXS) 2017, pages 23-30, Washington, D.C., June 26-30, 2017. ACM Press, New York, NY, USA. ISBN 978-1-4503-5001-3. DOI 10.1145/3086157.3086163. Acceptance rate 83.3% (5/6).
- Saurabh Hukerikar and Christian Engelmann. Language Support for Reliable Memory Regions. In Lecture Notes in Computer Science: Proceedings of the 29th International Workshop on Languages and Compilers for Parallel Computing, pages 73-87, Rochester, NY, USA, September 28-30, 2016. Springer Verlag, Berlin, Germany. ISBN 978-3-319-52708-6. ISSN 0302-9743. DOI 10.1007/978-3-319-52709-3_6. Acceptance rate 76.9% (20/26).
Peer-reviewed Conference Posters
- Christian Engelmann and Mohit Kumar. Resilience Design Patterns: A Structured Modeling Approach of Resilience in Computing Systems. Poster at the Workshop on Modeling and Simulation of Systems and Applications (ModSim) 2022, Seattle, WA, USA, August 10-12, 2022.
- Christian Engelmann and Rizwan Ashraf. Modeling and Simulation of Extreme-Scale Systems for Resilience by Design. Poster at the Workshop on Modeling and Simulation of Systems and Applications, Seattle, WA, USA, August 15-17, 2018.
- Onkar Patil, Saurabh Hukerikar, Frank Mueller, and Christian Engelmann. Exploring Use Cases for Non-Volatile Memories in Support of HPC Resilience. Poster at the 30th IEEE/ACM International Conference on High Performance Computing, Networking, Storage and Analysis (SC) 2017, Denver, CO, USA, November 12-17, 2017.
White Papers
- Mingyan Li, Robert A. Bridges, Pablo Moriano, Christian Engelmann, Feiyi Wang, and Ryan Adamson. Toward Effective Security/Reliability Situational Awareness via Concurrent Security-or-Fault Analytics . White paper accepted at the U.S. Department of Energy's ASCR Workshop on Cybersecurity and Privacy for Scientific Computing Ecosystems, November 3-5, 2021.
- Christian Engelmann. Resilience by Codesign (and not as an Afterthought). White paper accepted at the U.S. Department of Energy's Workshop on Reimagining Codesign 2021, March 16-18, 2021.
- Christian Engelmann, Rizwan Ashraf, and Saurabh Hukerikar. Extreme Heterogeneity with Resilience by Design (and not as an Afterthought). White paper accepted at the U.S. Department of Energy's Extreme Heterogeneity Virtual Workshop 2018, January 23-24, 2018.
Technical Reports
- Christian Engelmann, Rizwan Ashraf, Saurabh Hukerikar, Mohit Kumar, and Piyush Sao. Resilience Design Patterns: A Structured Approach to Resilience at Extreme Scale (Version 2.0). Technical Report, ORNL/TM-2022/2809, Oak Ridge National Laboratory, Oak Ridge, TN, USA, August 1, 2022. DOI 10.2172/1922296.
- Saurabh Hukerikar and Christian Engelmann. Resilience Design Patterns: A Structured Approach to Resilience at Extreme Scale (Version 1.2). Technical Report, ORNL/TM-2017/745, Oak Ridge National Laboratory, Oak Ridge, TN, USA, August 1, 2017. DOI 10.2172/1436045.
- Saurabh Hukerikar and Christian Engelmann. Resilience Design Patterns: A Structured Approach to Resilience at Extreme Scale (Version 1.1). Technical Report, ORNL/TM-2016/767, Oak Ridge National Laboratory, Oak Ridge, TN, USA, December 1, 2016. DOI 10.2172/1345793.
- Saurabh Hukerikar and Christian Engelmann. Resilience Design Patterns: A Structured Approach to Resilience at Extreme Scale (Version 1.0). Technical Report, ORNL/TM-2016/687, Oak Ridge National Laboratory, Oak Ridge, TN, USA, October 1, 2016. DOI 10.2172/1338552.
Talks and Lectures
- Christian Engelmann. Designing Smart and Resilient Extreme-Scale Systems. Invited talk at the 20th SIAM Conference on Parallel Processing for Scientific Computing (PP) 2022, Seattle, WA, USA, February 23-26, 2022.
- Christian Engelmann. Smart and Resilient Extreme-Scale Systems. Invited talk at the Workshop on Resilience in High Performance Computing (RESILIENTHPC), held in conjunction with the European Network on High-performance Embedded Architecture and Compilation (HiPEAC) Conference 2021, Budapest, Hungary, January 19, 2021.
- Christian Engelmann. Resilience by Design (and not as an Afterthought). Invited talk at the 23rd Workshop on Distributed Supercomputing (SOS) 2019, Asheville, NC, USA, March 26-29, 2018.
- Christian Engelmann and Rizwan Ashraf. Modeling and Simulation of Extreme-Scale Systems for Resilience by Design. Invited talk at the Workshop on Modeling and Simulation of Systems and Applications, Seattle, WA, USA, August 15-17, 2018.
- Christian Engelmann. Pattern-based Modeling of Fail-stop and Soft-error Resilience for Iterative Linear Solvers. Invited talk at the 18th SIAM Conference on Parallel Processing for Scientific Computing (PP) 2018, Tokyo, Japan, March 7-10, 2018.
- Christian Engelmann. Resilience Design Patterns: A Structured Approach to Resilience at Extreme Scale. Invited talk at the 18th SIAM Conference on Parallel Processing for Scientific Computing (PP) 2018, Tokyo, Japan, March 7-10, 2018.
- Christian Engelmann. Toward A Fault Model And Resilience Design Patterns For Extreme Scale Systems. Keynote talk at the 8th Workshop on Resiliency in High Performance Computing (Resilience) in Clusters, Clouds, and Grids, held in conjunction with the 21st European Conference on Parallel and Distributed Computing (Euro-Par) 2015, Vienna, Austria, August 24-28, 2015.
Symbols: Abstract, Publication, Presentation, BibTeX Citation