| Summary: This solution provides high availability for high-performance computing system services with efficient redundancy strategies for head and service nodes. It relies on virtual synchrony, i.e., state-machine replication, utilizing a process group communication system for service group membership management and for reliable, totally ordered message delivery. The proof-of-concept prototypes offer 99.9997% high availability for the Torque resource manager and the Parallel Virtual File System Metadata Server. |
This work paves the way for high availability in high-performance computing (HPC) by focusing on efficient redundancy strategies for head and service nodes. These nodes represent single points of failure and control for an entire HPC system as they render it inaccessible and unmanageable in case of a single node failure until manual repair. The approach relies on virtual synchrony, i.e., state-machine replication, utilizing a process group communication system for service group membership management and reliable, totally ordered message delivery. This replication method may be implemented internally, i.e., by modifying the service to be replicated to support redundant instances, or externally, i.e., by wrapping around an unmodified service, replicating input to multiple instances, and unifying output from these instances. Internal replication offers usually more performance, while external replication is typically easier to implement.
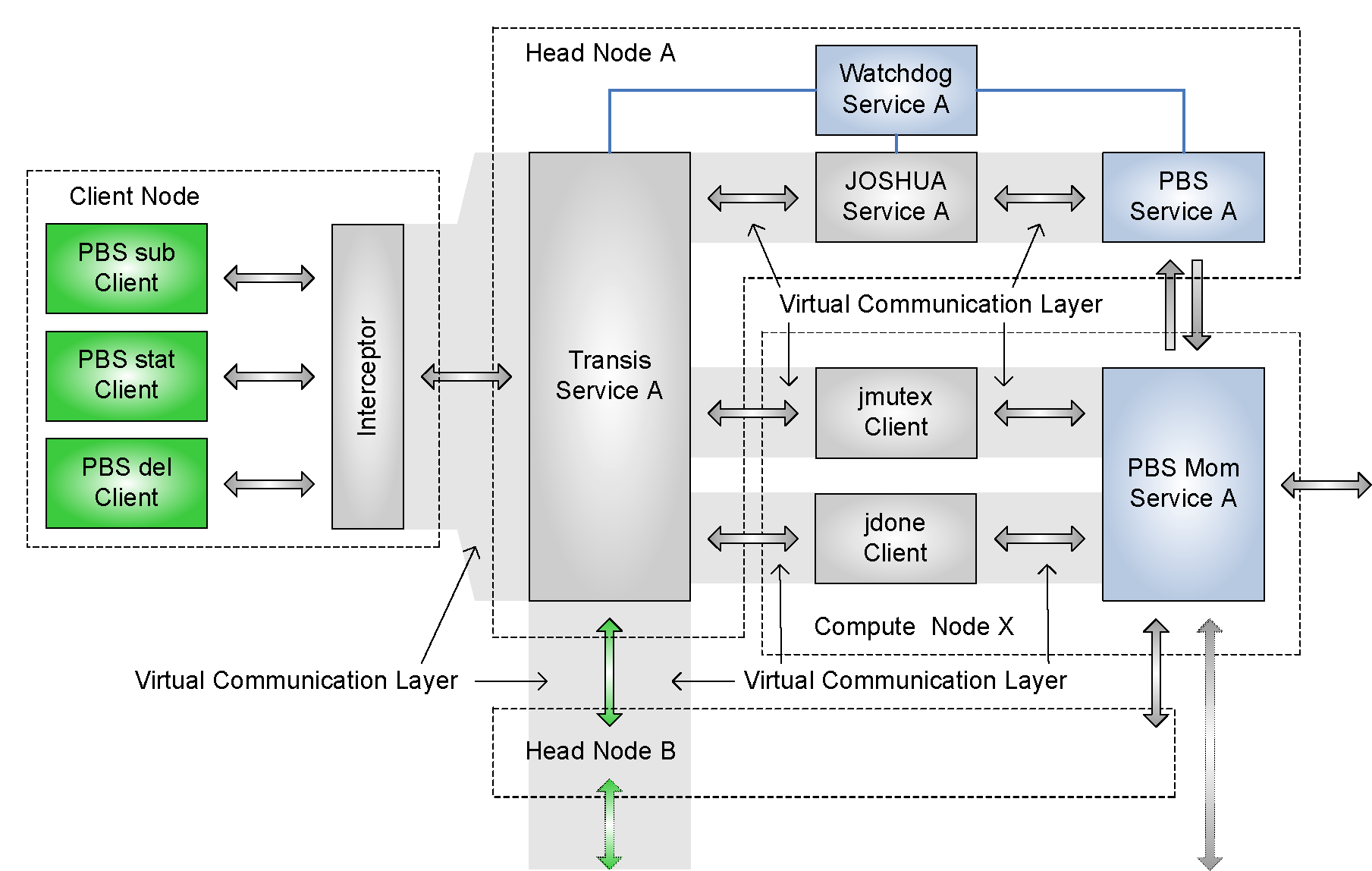
One of the most important HPC system services running on the head node is the job and resource manager. If it goes down, all currently running jobs lose the service they report back to. They have to be restarted once the head node is up and running again. JOSHUA is a generic solution that provides a virtually synchronous environment for continuous availability without any interruption of service and without any loss of state. Replication is performed externally (Figure 1) via the Portable Batch System (PBS) service interface without the need to modify any service code. This makes it portable to most HPC job and resource managers as the PBS service interface is supported widely. The results, as well as, availability analysis of our proof-of-concept prototype implementation show that continuous availability can be provided by JOSHUA with an acceptable performance.
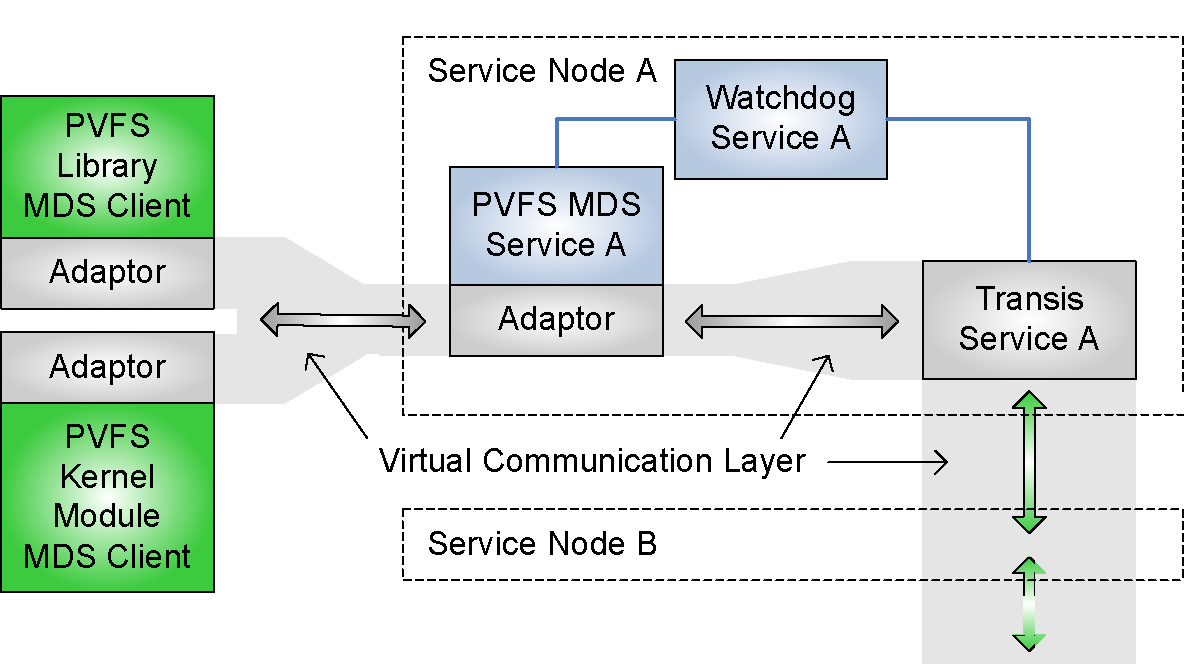
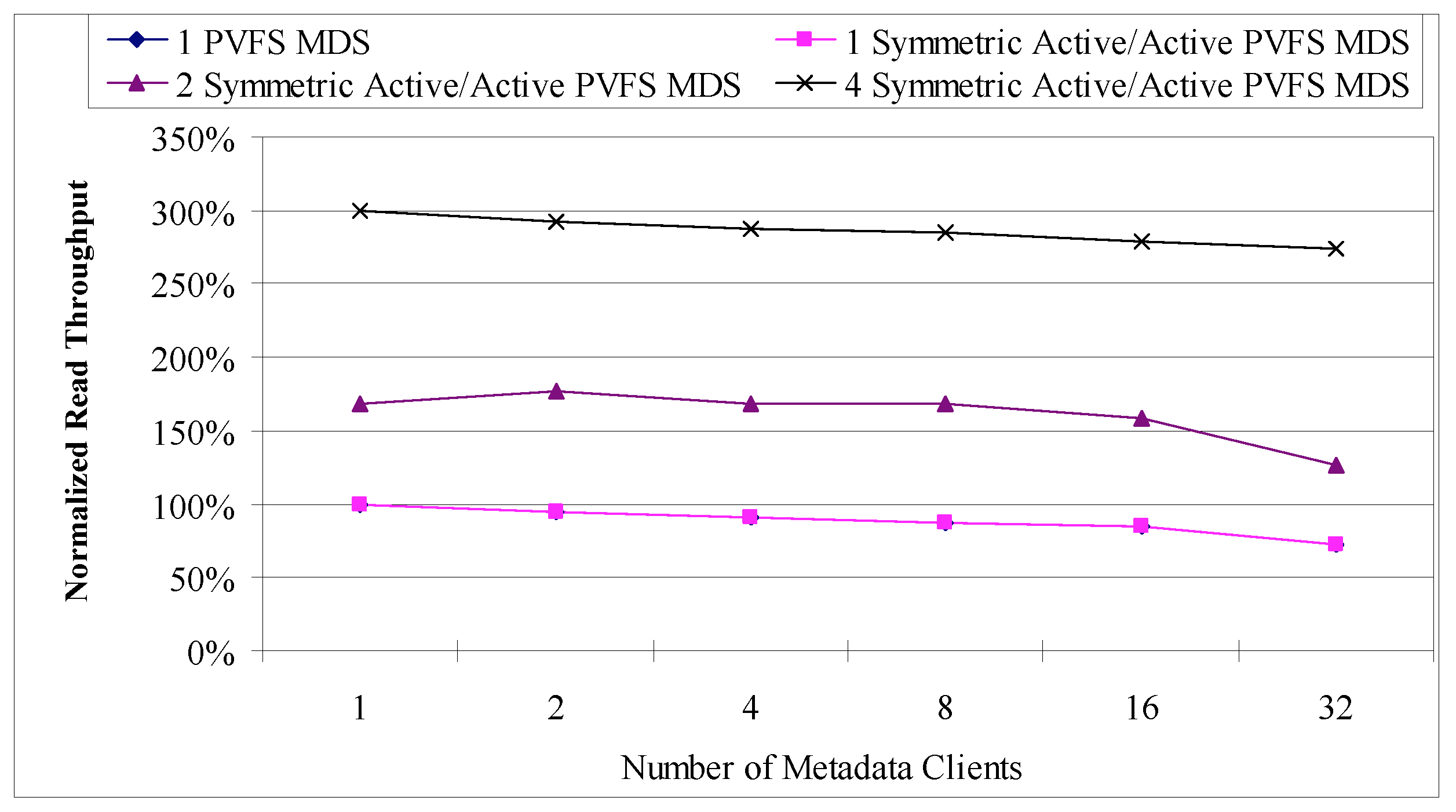
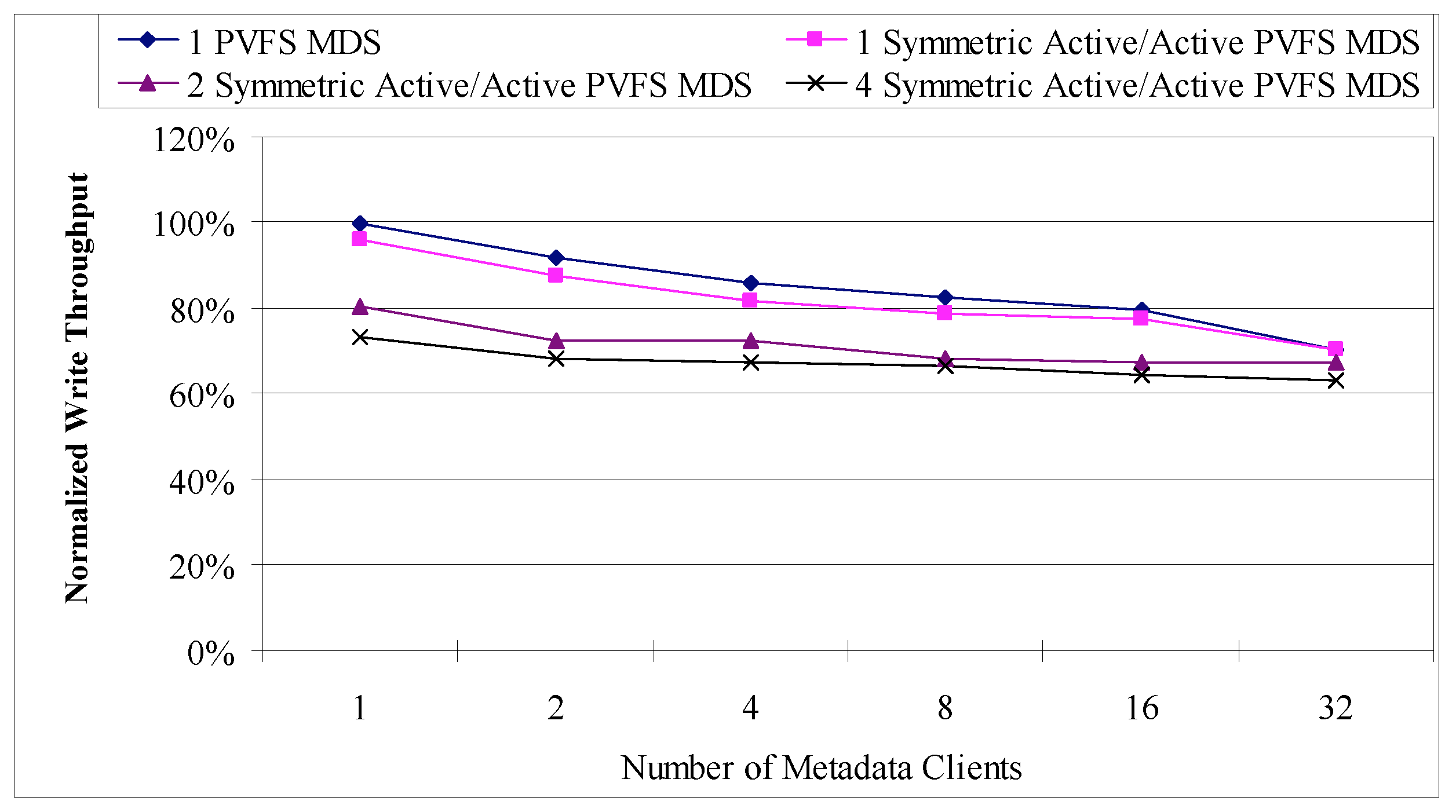
The metadata service (MDS) of a networked parallel file system is another critical single point of failure. An interruption of service typically results in the failure of currently running applications utilizing its file system. A loss of state requires repairing the entire file system, which could take days on large-scale systems, and may cause loss of data. The developed proof-of-concept prototype for the MDS of the Parallel Virtual File System (PVFS) offers symmetric active/active replication using virtual synchrony with an internal replication implementation (Figure 2). In addition to providing high availability, this solution is taking advantage of the internal replication implementation by load balancing MDS read requests, improving performance over the non-replicated MDS. The results show that MDS high availability can be achieved with an acceptable performance (Figures 3 and 4).
Assuming a mean-time to failure of 5,000 hours for a single head or service node, the presented solutions improve service availability from 99.285% (2 nines) of a single node to 99.995% (4 nines) in a two-node system, and to 99.99996% (6 nines) with three nodes (Figure 5). Replication beyond three nodes may not provide further benefits, other than performance increases due to load balancing, since after three nodes, catastrophic incidents, such as earthquakes, hurricanes, and tornados, have a higher impact on availability than component failures.
|
|
|
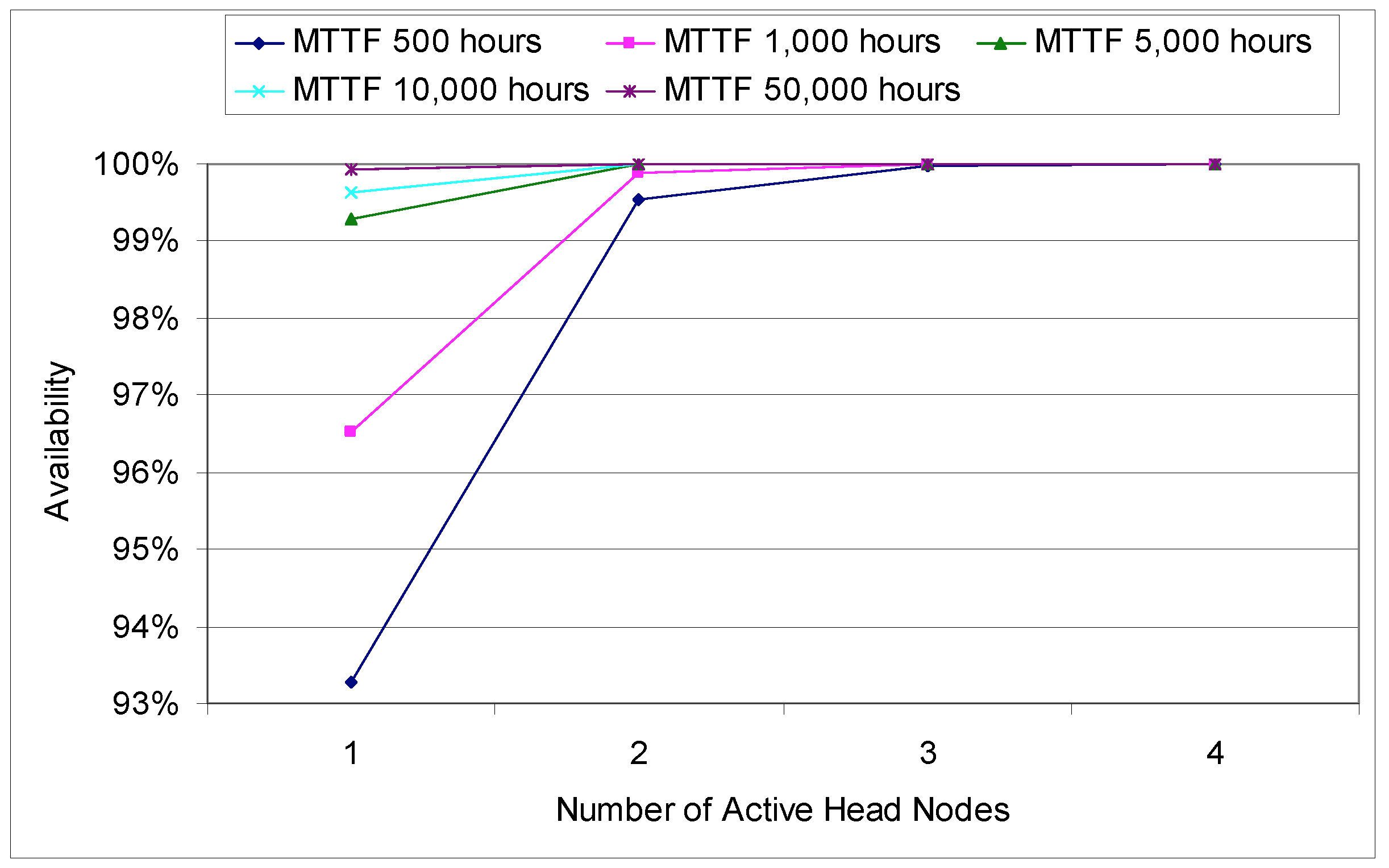 Figure 5: Service availability improvement |
Research Projects
- 2004-07: MOLAR: Modular Linux and Adaptive Runtime Support for High-End Computing
- 2004-06: Reliability, Availability, and Serviceability (RAS) for Terascale Computing
Funding Sources
- Office of Advanced Scientific Computing Research, Office of Science, U.S. Department of Energy
- Laboratory Directed Research and Development, Oak Ridge National Laboratory
Participating Institutions
Peer-reviewed Journal Publications
- Xubin (Ben) He, Li Ou, Christian Engelmann, Xin Chen, and Stephen L. Scott. Symmetric Active/Active Metadata Service for High Availability Parallel File Systems. Journal of Parallel and Distributed Computing (JPDC), volume 69, number 12, pages 961-973, December 1, 2009. Elsevier B.V, Amsterdam, The Netherlands. ISSN 0743-7315. DOI 10.1016/j.jpdc.2009.08.004.



- Christian Engelmann, Stephen L. Scott, Chokchai (Box) Leangsuksun, and Xubin (Ben) He. Symmetric Active/Active High Availability for High-Performance Computing System Services. Journal of Computers (JCP), volume 1, number 8, pages 43-54, December 1, 2006. Academy Publisher, Oulu, Finland. ISSN 1796-203X. DOI 10.4304/jcp.1.8.43-54.
Peer-reviewed Conference Publications
- Christian Engelmann, Stephen L. Scott, Chokchai (Box) Leangsuksun, and Xubin (Ben) He. Symmetric Active/Active Replication for Dependent Services. In Proceedings of the 3rd International Conference on Availability, Reliability and Security (ARES) 2008, pages 260-267, Barcelona, Spain, March 4-7, 2008. IEEE Computer Society, Los Alamitos, CA, USA. ISBN 978-0-7695-3102-1. DOI 10.1109/ARES.2008.64. Acceptance rate 21.1% (40/190).

- Li Ou, Christian Engelmann, Xubin (Ben) He, Xin Chen, and Stephen L. Scott. Symmetric Active/Active Metadata Service for Highly Available Cluster Storage Systems. In Proceedings of the 19th IASTED International Conference on Parallel and Distributed Computing and Systems (PDCS) 2007, Cambridge, MA, USA, November 19-21, 2007. ACTA Press, Calgary, AB, Canada. ISBN 978-0-88986-703-1. Acceptance rate 49%.
- Li Ou, Xubin (Ben) He, Christian Engelmann, and Stephen L. Scott. A Fast Delivery Protocol for Total Order Broadcasting. In Proceedings of the 16th IEEE International Conference on Computer Communications and Networks (ICCCN) 2007, pages 730-734, Honolulu, HI, USA, August 13-16, 2007. IEEE Computer Society, Los Alamitos, CA, USA. ISBN 978-1-42441-251-8. ISSN 1095-2055. DOI 10.1109/ICCCN.2007.4317904. Acceptance rate 29.1% (160/550).
- Christian Engelmann, Stephen L. Scott, Chokchai (Box) Leangsuksun, and Xubin (Ben) He. On Programming Models for Service-Level High Availability. In Proceedings of the 2nd International Conference on Availability, Reliability and Security (ARES) 2007, pages 999-1006, Vienna, Austria, April 10-13, 2007. IEEE Computer Society, Los Alamitos, CA, USA. ISBN 0-7695-2775-2. DOI 10.1109/ARES.2007.109. Acceptance rate 28.3% (60/212).
- Kai Uhlemann, Christian Engelmann, and Stephen L. Scott. JOSHUA: Symmetric Active/Active Replication for Highly Available HPC Job and Resource Management. In Proceedings of the 8th IEEE International Conference on Cluster Computing (Cluster) 2006, pages 1-10, Barcelona, Spain, September 25-28, 2006. IEEE Computer Society, Los Alamitos, CA, USA. ISBN 1-4244-0328-6. ISSN 1552-5244. DOI 10.1109/CLUSTR.2006.311855. Acceptance rate 33.1% (42/127).
Peer-reviewed Workshop Publications
- Christian Engelmann, Stephen L. Scott, Chokchai (Box) Leangsuksun, and Xubin (Ben) He. Symmetric Active/Active High Availability for High-Performance Computing System Services: Accomplishments and Limitations. In Proceedings of the 8th IEEE International Symposium on Cluster Computing and the Grid (CCGrid) 2008: Workshop on Resiliency in High Performance Computing (Resilience) 2008, pages 813-818, Lyon, France, May 19-22, 2008. IEEE Computer Society, Los Alamitos, CA, USA. ISBN 978-0-7695-3156-4. DOI 10.1109/CCGRID.2008.78.
- Christian Engelmann, Stephen L. Scott, Chokchai (Box) Leangsuksun, and Xubin (Ben) He. Transparent Symmetric Active/Active Replication for Service-Level High Availability. In Proceedings of the 7th IEEE International Symposium on Cluster Computing and the Grid (CCGrid) 2007: 7th International Workshop on Global and Peer-to-Peer Computing (GP2PC) 2007, pages 755-760, Rio de Janeiro, Brazil, May 14-17, 2007. IEEE Computer Society, Los Alamitos, CA, USA. ISBN 0-7695-2833-3. DOI 10.1109/CCGRID.2007.116.
- Christian Engelmann, Stephen L. Scott, Chokchai (Box) Leangsuksun, and Xubin (Ben) He. Towards High Availability for High-Performance Computing System Services: Accomplishments and Limitations. In Proceedings of the 4th High Availability and Performance Workshop (HAPCW) 2006, in conjunction with the 7th Los Alamos Computer Science Institute (LACSI) Symposium 2006, Santa Fe, NM, USA, October 17, 2006.
- Christian Engelmann, Stephen L. Scott, Chokchai (Box) Leangsuksun, and Xubin (Ben) He. Active/Active Replication for Highly Available HPC System Services. In Proceedings of the 1st International Conference on Availability, Reliability and Security (ARES) 2006: 1st International Workshop on Frontiers in Availability, Reliability and Security (FARES) 2006, pages 639-645, Vienna, Austria, April 20-22, 2006. IEEE Computer Society, Los Alamitos, CA, USA. ISBN 0-7695-2567-9. DOI 10.1109/ARES.2006.23.
- Christian Engelmann and Stephen L. Scott. Concepts for High Availability in Scientific High-End Computing. In Proceedings of the 3rd High Availability and Performance Workshop (HAPCW) 2005, in conjunction with the 6th Los Alamos Computer Science Institute (LACSI) Symposium 2005, Santa Fe, NM, USA, October 11, 2005.
- Christian Engelmann and Stephen L. Scott. High Availability for Ultra-Scale High-End Scientific Computing. In Proceedings of the 2nd International Workshop on Operating Systems, Programming Environments and Management Tools for High-Performance Computing on Clusters (COSET-2) 2005, in conjunction with the 19th ACM International Conference on Supercomputing (ICS) 2005, Cambridge, MA, USA, June 19, 2005.
Peer-reviewed Conference Posters
- Stephen L. Scott, Christian Engelmann, Hong H. Ong, Geoffroy R. Vallée, Thomas Naughton, Anand Tikotekar, George Ostrouchov, Chokchai (Box) Leangsuksun, Nichamon Naksinehaboon, Raja Nassar, Mihaela Paun, Frank Mueller, Chao Wang, Arun B. Nagarajan, Jyothish Varma, Xubin (Ben) He, Li Ou, and Xin Chen. Resiliency for High-Performance Computing Systems. Poster at the 1st High-Performance Computer Science Week (HPCSW) 2008, Denver, CO, USA, March 30 – April 5, 2008.
Talks and Lectures
- Christian Engelmann. System Resilience Research at ORNL in the Context of HPC. Invited talk at the Institut National de Recherche en Informatique et en Automatique (INRIA), Rennes, France, May 15, 2009.
- Christian Engelmann. High-Performance Computing Research at Oak Ridge National Laboratory. Invited talk at the Reading Annual Computational Science Workshop, Reading, United Kingdom, December 8, 2008.
- Christian Engelmann. Modular Redundancy in HPC Systems: Why, Where, When and How?. Invited talk at the 1st HPC Resiliency Summit: Workshop on Resiliency for Petascale HPC 2008, in conjunction with the 1st Los Alamos Computer Science Symposium (LACSS) 2008, Santa Fe, NM, USA, October 15, 2008.
- Christian Engelmann. Resiliency for High-Performance Computing. Invited talk at the 2nd Collaborative and Grid Computing Technologies Workshop (CGCTW) 2008, Cancun, Mexico, April 10-12, 2008.
- Christian Engelmann. Advanced Fault Tolerance Solutions for High Performance Computing. Seminar at the Laboratoire d'Analyse et d’Architecture des Systémes, Centre National de la Recherche Scientifique, Toulouse, France, February 11, 2008.
- Christian Engelmann. Service-Level High Availability in Parallel and Distributed Systems. Seminar at the Department of Computer Science, University of Reading, Reading, United Kingdom, October 10, 2007.
- Christian Engelmann. Advanced Fault Tolerance Solutions for High Performance Computing. Invited talk at the Workshop on Trends, Technologies and Collaborative Opportunities in High Performance and Grid Computing (WTTC) 2007, Khon Kean, Thailand, June 8, 2007.
- Christian Engelmann. Advanced Fault Tolerance Solutions for High Performance Computing. Invited talk at the Workshop on Trends, Technologies and Collaborative Opportunities in High Performance and Grid Computing (WTTC) 2007, Bangkok, Thailand, June 4-5, 2007.
- Christian Engelmann. Towards High Availability for High-Performance Computing System Services: Accomplishments and Limitations. Seminar at the Department of Computer Science, University of Reading, Reading, United Kingdom, March 14, 2007.
- Christian Engelmann. High Availability for Ultra-Scale High-End Scientific Computing. Seminar at the Department of Computer Science, University of Reading, Reading, United Kingdom, June 9, 2006.
- Stephen L. Scott and Christian Engelmann. Advancing Reliability, Availability and Serviceability for High-Performance Computing. Seminar at the Institute of Graphics and Parallel Processing, Johannes Kepler University, Linz, Austria, April 19, 2006.
- Christian Engelmann. High Availability for Ultra-Scale High-End Scientific Computing. Seminar at the Department of Computer Science, University of Reading, Reading, United Kingdom, October 18, 2005.
- Christian Engelmann. High Availability for Ultra-Scale High-End Scientific Computing. Seminar at the Department of Mathematics and Computer Science, Fayetteville State University, Fayetteville, NC, USA, September 26, 2005.
- Christian Engelmann. High Availability for Ultra-Scale High-End Scientific Computing. Seminar at the Department of Computer Science, University of Reading, Reading, United Kingdom, May 13, 2005.
- Christian Engelmann. High Availability for Ultra-Scale High-End Scientific Computing. Seminar at the Center for Entrepreneurship and Information Technology, Louisiana Tech University, Ruston, LA, USA, April 15, 2005.
Co-advised Theses
- Matthias Weber. High Availability for the Lustre File System. Master’s thesis, Department of Computer Science, University of Reading, UK, March 14, 2007. Thesis research performed at Oak Ridge National Laboratory. Double diploma in conjunction with the Department of Engineering I, Technical College for Engineering and Economics (FHTW) Berlin, Germany. Advisors: Prof. Vassil N. Alexandrov (University of Reading); Christian Engelmann (Oak Ridge National Laboratory).
- Kai Uhlemann. High Availability for High-End Scientific Computing. Master’s thesis, Department of Computer Science, University of Reading, UK, March 6, 2006. Thesis research performed at Oak Ridge National Laboratory. Double diploma in conjunction with the Department of Engineering I, Technical College for Engineering and Economics (FHTW) Berlin, Germany. Advisors: Prof. Vassil N. Alexandrov (University of Reading); George A. (Al) Geist and Christian Engelmann (Oak Ridge National Laboratory).
Theses
- Christian Engelmann. Symmetric Active/Active High Availability for High-Performance Computing System Services. PhD thesis, Department of Computer Science, University of Reading, UK, December 8, 2008. Thesis research performed at Oak Ridge National Laboratory. Advisor: Prof. Vassil N. Alexandrov (University of Reading).
Symbols: Abstract, Publication, Presentation, BibTeX Citation