| Summary: This operating system and runtime environment solution combines scalable group membership management, reuse of network connections, transparent coordinated checkpoint scheduling, a job pause feature, and full/incremental checkpointing. The job pause allows compute nodes to remain active and roll back parallel applications to the last checkpoint. The hybrid checkpointing alternates between full and incremental checkpoints, where only data is captured that changed since the last checkpoint. |
Checkpoint/restart has become a requirement for long-running parallel jobs in large-scale high-performance computing (HPC) systems due to a mean-time-to-failure (MTTF) in the order of hours. After a failure, checkpoint/restart mechanisms generally require a complete restart of a Message Passing Interface (MPI) job from the last saved checkpoint. A complete restart, however, is unnecessary since all but one compute node are typically still alive. Furthermore, a restart may result in lengthy job requeuing even though the original job had not exceeded its time quantum. Moreover, system-level checkpointing solutions capture full process images, even though only a subset of the process image changes between checkpoints.
The developed proof-of-concept prototype includes enhancements in support of scalable group communication for membership management (Figure 1), reuse of network connections, transparent coordinated checkpoint scheduling, a job pause feature, and full/incremental checkpointing (Figures 2 and 3). It is based on the Local Area Multicomputer MPI implementation (LAM/MPI) and the Berkeley Lab Checkpoint/Restart (BLCR) solution. The transparent mechanism for job pause allows live nodes to remain active and roll back to the last checkpoint, while failed nodes are dynamically replaced by spares before resuming from the last checkpoint. A minimal overhead of 5.6% is incurred in case migration takes place, while the regular checkpoint overhead remains unchanged. The hybrid checkpointing technique alternates between full and incremental checkpoints: At incremental checkpoints, only data changed since the last checkpoint is captured. This results in significantly reduced checkpoint sizes and overheads with only moderate increases in restart overhead. After accounting for cost and savings, benefits due to incremental checkpoints are an order of magnitude larger than overheads on restarts.
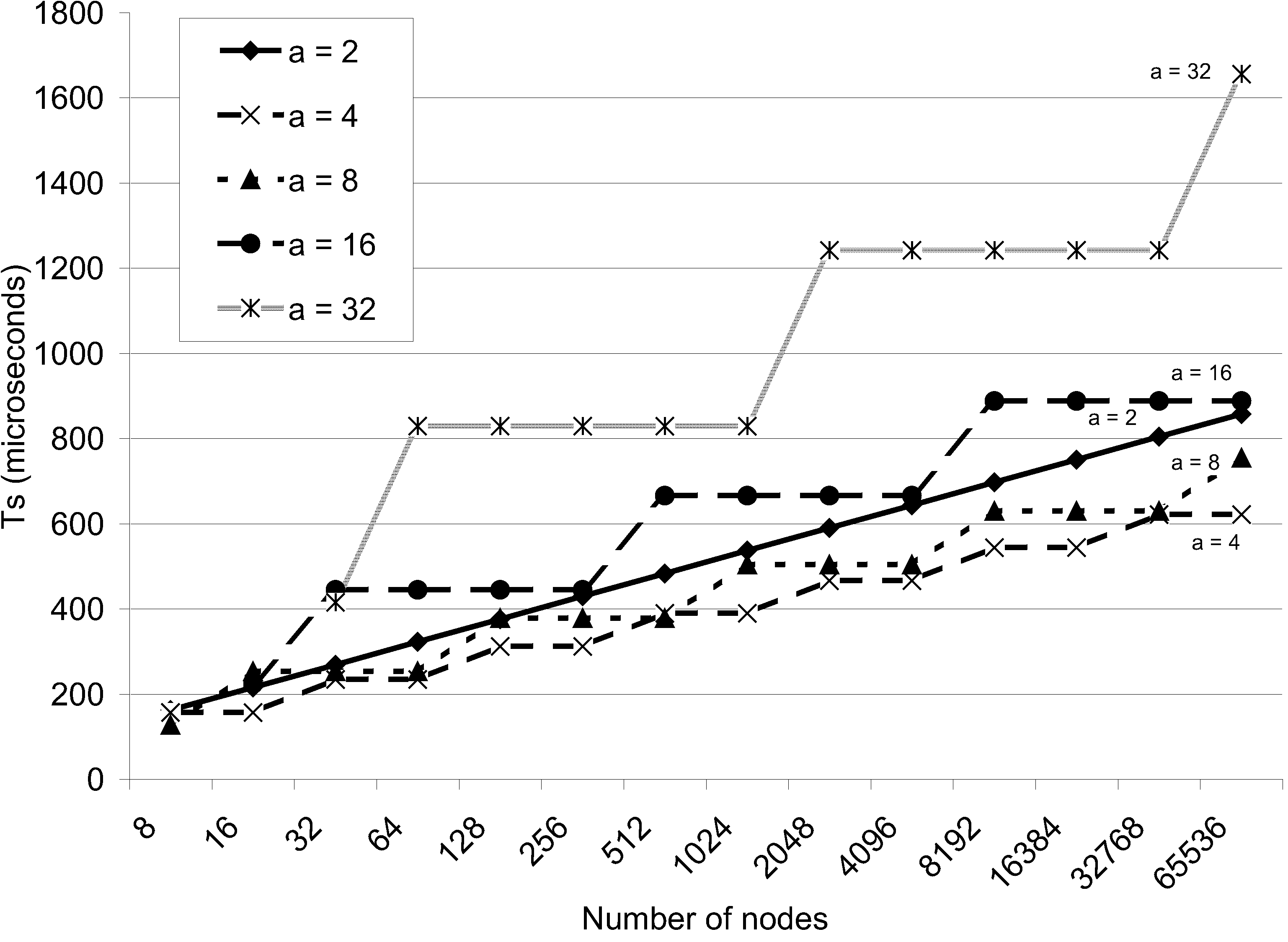 Figure 1: Membership stabilization after a failure |
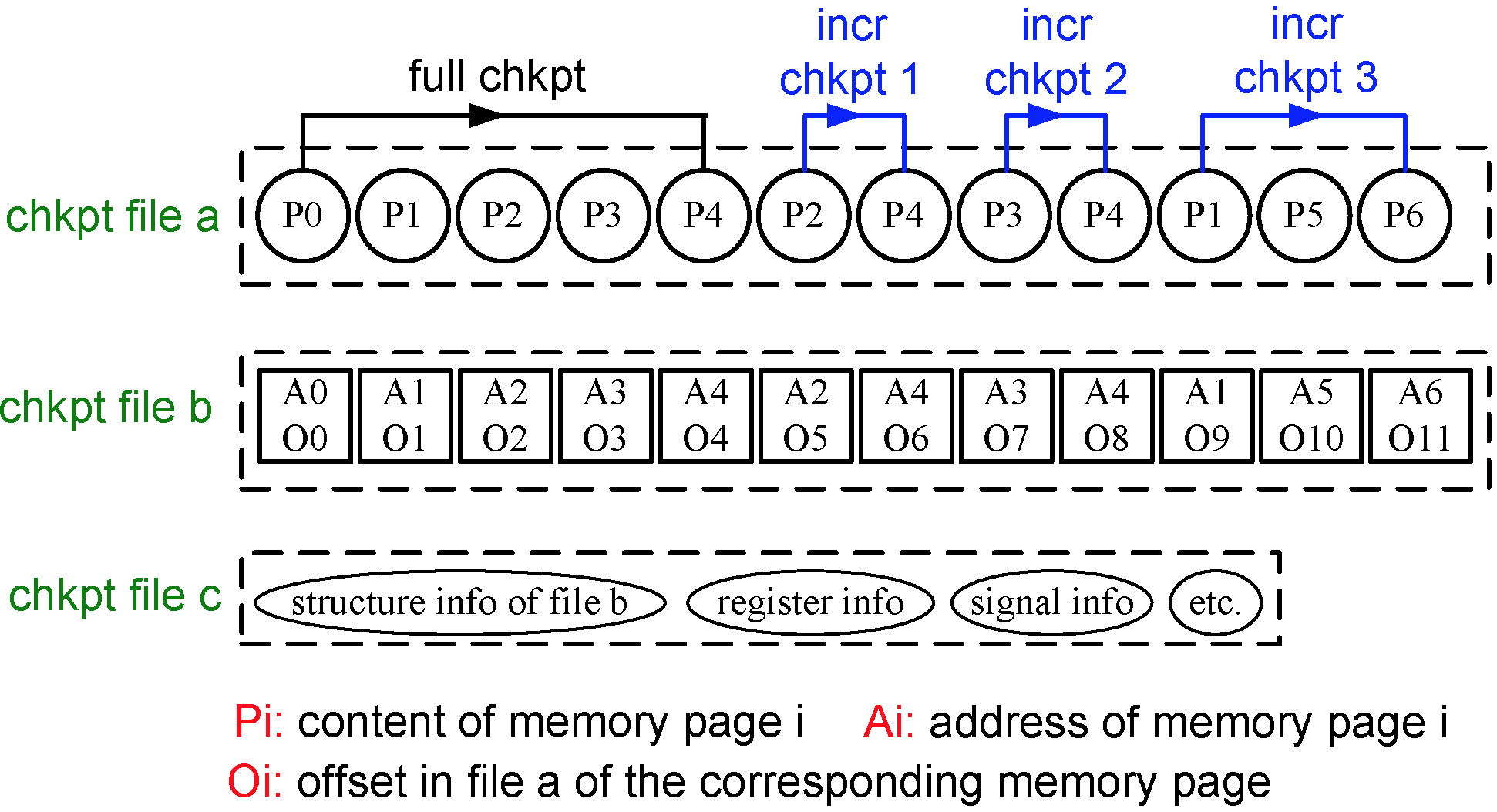 Figure 2: Incremental checkpoint file structure |
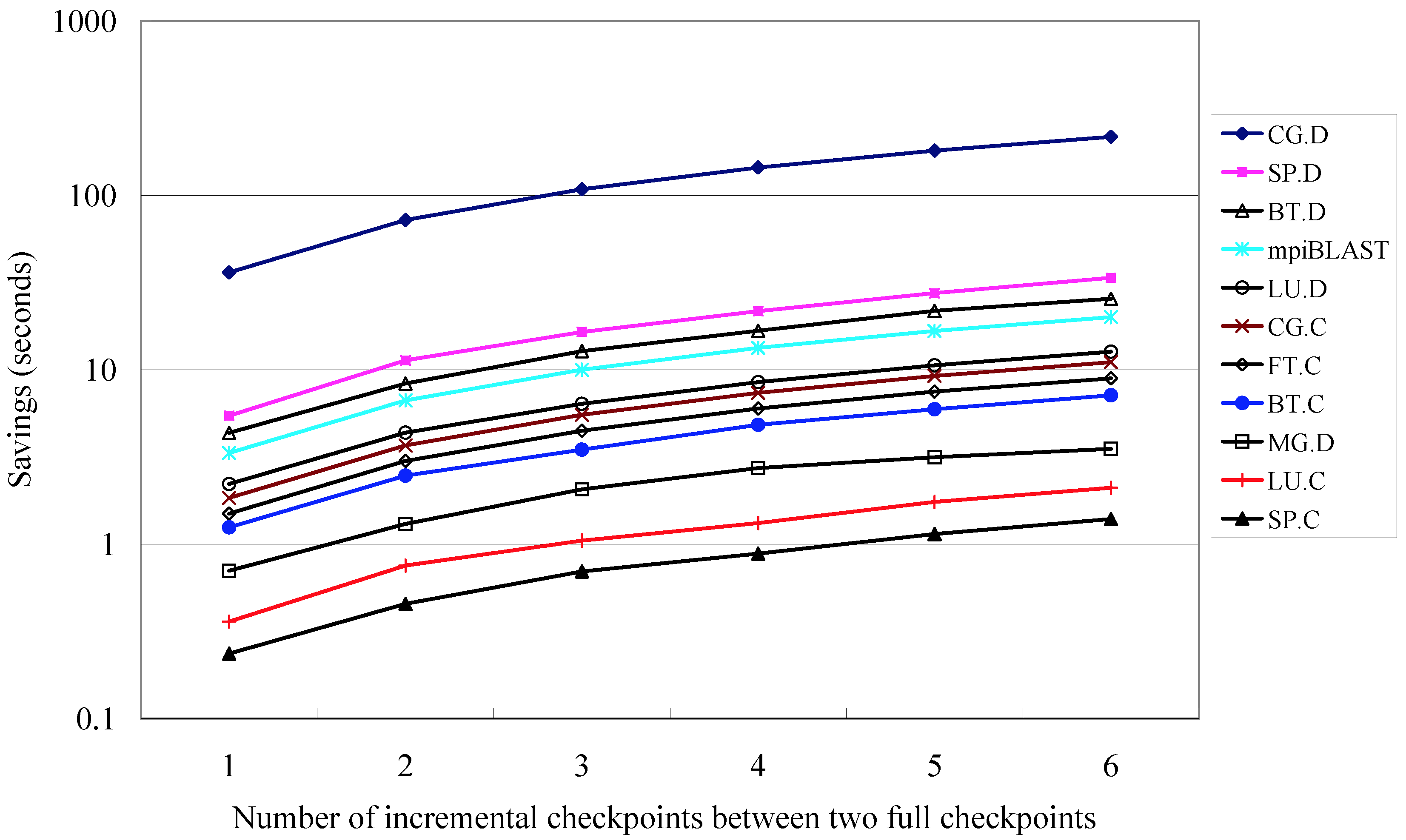 Figure 3: Hybrid full/incremental checkpoint savings |
Research Projects
- 2008-11: Reliability, Availability, and Serviceability (RAS) for Petascale High-End Computing and Beyond
- 2004-07: MOLAR: Modular Linux and Adaptive Runtime Support for High-End Computing
Funding Sources
- Office of Advanced Scientific Computing Research, Office of Science, U.S. Department of Energy
Participating Institutions
Peer-reviewed Conference Publications
- Chao Wang, Frank Mueller, Christian Engelmann, and Stephen L. Scott. Hybrid Checkpointing for MPI Jobs in HPC Environments. In Proceedings of the 16th IEEE International Conference on Parallel and Distributed Systems (ICPADS) 2010, pages 524-533, Shanghai, China, December 8-10, 2010. IEEE Computer Society, Los Alamitos, CA, USA. ISBN 978-0-7695-4307-9. DOI 10.1109/ICPADS.2010.48. Acceptance rate 29.6% (77/188).




- Chao Wang, Frank Mueller, Christian Engelmann, and Stephen L. Scott. A Job Pause Service under LAM/MPI+BLCR for Transparent Fault Tolerance. In Proceedings of the 21st IEEE International Parallel and Distributed Processing Symposium (IPDPS) 2007, pages 1-10, Long Beach, CA, USA, March 26-30, 2007. ACM Press, New York, NY, USA. ISBN 978-1-59593-768-1. DOI 10.1109/IPDPS.2007.370307. Acceptance rate 26% (109/419).
Technical Reports
- Chao Wang, Frank Mueller, Christian Engelmann, and Stephen L. Scott. Hybrid Full/Incremental Checkpoint/Restart for MPI Jobs in HPC Environments. Technical Report, ORNL/TM-2010/162, Oak Ridge National Laboratory, Oak Ridge, TN, USA, August 1, 2010.
Talks and Lectures
- Christian Engelmann. Resilience Challenges and Solutions for Extreme-Scale Supercomputing. Invited talk at the United States Naval Academy, Annapolis, MD, USA, February 18, 2016.
- Christian Engelmann. Resilience Challenges and Solutions for Extreme-Scale Supercomputing. Invited talk at the 19th Workshop on Distributed Supercomputing (SOS) 2015, Park City, UT, USA, March 2-5, 2015.
- Christian Engelmann. Resilience and Hardware/Software Co-design for Extreme-Scale Supercomputing. Seminar at the Barcelona Supercomputing Center, Barcelona, Spain, July 27, 2011.
- Christian Engelmann. Beyond Application-Level Checkpoint/Restart – Advanced Software Approaches for Fault Resilience. Talk at the 39th SPEEDUP Workshop on High Performance Computing, Zurich, Switzerland, September 6, 2010.
- Christian Engelmann and Stephen L. Scott. Reliability, Availability, and Serviceability (RAS) for Petascale High-End Computing and Beyond. Talk at the Forum to Address Scalable Technology for Runtime and Operating Systems (FAST-OS) Workshop, in conjunction with the USENIX Federated Conferences Week (USENIX) 2010, Boston MA, USA, June 22, 2010.
- Christian Engelmann. System Resilience Research at ORNL in the Context of HPC. Invited talk at the Institut National de Recherche en Informatique et en Automatique (INRIA), Rennes, France, May 15, 2009.
- Christian Engelmann. High-Performance Computing Research at Oak Ridge National Laboratory. Invited talk at the Reading Annual Computational Science Workshop, Reading, United Kingdom, December 8, 2008.
- Christian Engelmann. Resiliency for High-Performance Computing. Invited talk at the 2nd Collaborative and Grid Computing Technologies Workshop (CGCTW) 2008, Cancun, Mexico, April 10-12, 2008.
Symbols: Abstract, Publication, Presentation, BibTeX Citation